
Python基础
持续更新
安装:
www.python.org下载安装,跨平台,注意windows安装版要勾选 Add python.exe to PATH
验证:
Python交互模式:
命令行模式键入python进入Python交互模式
print('hello world'),输出 hello world即可
命令行模式键入python hello.py,可运行一个.py文件
IDE:
Thonny 适合新手,官网:thonny.org
我喜欢 PyCharm,官网:www.jetbrains.com/zh-cn/pycharm/
输入与输出:
name = input()
print('hello',name)python大小写敏感
注释
单行注释:
# 单行注释多行注释:
''' 多行注释 '''数据类型
整数
允许以"_"分隔比较大的整数,例如:1000_000_00 与 100000000一样
浮点数
也就是小数,很大的浮点数用科学计数法表示,10用e代替,例:1.23×10的9次方就是1.23e9,0.000012就是1.2e-5
字符串
以''或""括起来任意文本,字符串内的"" ''用转义字符 \ 标识
布尔值
True、False,可以用and、or、not运算(与、或、非),与全真为真,或一个真就是真
空值
None,None不是0,0是有意义的,None是一个特殊的空值
此外还提供了列表、字典多种数据类型,允许创建自定义数据类型
字节
bytes类型用带b前缀的单引号或双引号表示
例如:x = b'abc'
变量
变量可以是整数、浮点、字符串、布尔等任意类型
python是动态语言,java是静态语言,静态语言在定义变量时,要指定变量的类型,动态语言不用
动态语言更灵活
a = 'ABC'
b = a
a = 'XYZ'
print(b)输出结果为:ABC
内存中创建变量a,创建变量b,创建ABC字符串,将a指向ABC字符串,变量b指向了'ABC'字符串,创建XYZ字符转,变量a指向XYZ字符转
常量
不能改变的变量,习惯上用全部大写的变量名表示常量,跟java不同,常量是可以被改变的,所以为了区分用大写命名
计算
除法:
"/" 结果是浮点数,精确除
"//" 结果是整数,称为地板除
取余:
"%"两个整数相除的余数,结果也是整数
次幂:
"5**3",意思就是5的3次幂
python的整数与浮点数没有大小限制
字符编码
字符是一种数据类型,但字符串有一个编码问题
计算机只能处理数字,如果要处理文本,必须先把文本转换成数字才能处理
8比特(bit)作为一个字节(byte),即1Byte=8bit,byte是计算机的基本单位,bit是计算机最小单位
一个字节表示的最大整数就是255(二进制全是1的8位bit,转换成十进制就是255)
两个字节表示的最大整数就是65535
最早的计算机只有127个字符被编码到计算机中,也就是大小写英文字母、数字和一些符号,这个编码表就是ASCII编码(1个字节)
为了各国家语言的编码统一,出现了Unicode字符集(2个字节)
Unicode将所有语言都统一到一套编码里,解决了各国家之间字符出现的乱码问题,但是Unicode是2个字节,如果英文也使用unicode编码,就需要用 0 补全前面的一个字节
例如:A的Unicode编码就变成了 00000000 01000001
这种形式就会导致英文的存储比之前的ASCII编码多出一倍存储空间,所以Unicode编码转化为”可变长编码“的UTF-8编码
UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如此英文字符就能节省空间
如今计算机系统通用的字符编码工作方式:
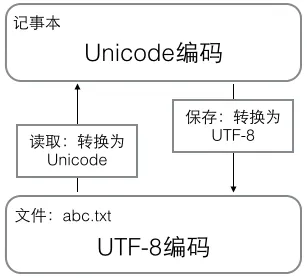
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
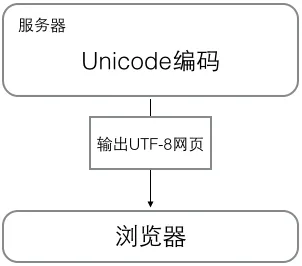
所以很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码
字符串
研究Python字符串,前提需要清楚以上字符编码
Python3版本中,字符串是以Unicode编码的,也就是Python字符串支持多语言
print('包含中文的str')单个字符可以用ord()函数获取字符的整数表示:
ord('A')
ord('中')chr()函数可以把编码转换为对应字符:
chr(66)
chr(25991)Python字符串是str,在内存中以Unicode表示,一个字符对应若干字节
如果在网络上传输或保存在磁盘上,就需要把str变成字节 bytes
计算str、bytes包含多少个字符,用len()函数:
# 查询str字符数
len('ABC')
len('中文')
# 查询bytes字节数
len(b'ABC')
len('中文'.encode('utf-8'))编码开头注释
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码
字符串中的占位符
'Hello, %s' % 'world' # 输出:Hello,world
'Hi, %s, you have $%d.' % ('Michael', 1000000) # 输出:Hi,Michael,you have $1000000%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略
常见占位符:
%s 会将任何数据类型转换为字符串
'Age: %s. Gender: %s' % (25, True)
# 输出:'Age: 25. Gender: True'%的转译使用%%
'growth rate: %d %%' % 7
# 输出:'growth rate: 7 %'f-string
使用以f开头的字符串,称之为f-string,它和普通字符串不同之处在于,字符串如果包含{xxx},就会以对应的变量替换:
r = 2.5
s = 3.14 * r ** 2
print(f'The area of a circle with radius {r} is {s:.2f}')
# 输出:The area of a circle with radius 2.5 is 19.62练习
小明的成绩从去年的72分提升到了今年的85分,请计算小明成绩提升的百分点,并用字符串格式化显示出'xx.x%',只保留小数点后1位:
# -*- coding: utf-8 -*-
s1 = 72
s2 = 85
r = ((85-72)/72)*100
print('小明成绩提升百分点%.1f' % r)
# 输出:小明成绩提升百分点18.1
list 列表
Python内置的一种数据类型是列表:list。list是一种有序的列表(非集合或数组),可以随时添加和删除其中的元素。
classmates = ['Michael', 'Bob', 'Tracy']查询元素个数
classmates = ['Michael', 'Bob', 'Tracy']
len(classmates)表示列表中的各元素
classmates = ['Michael', 'Bob', 'Tracy']
classmates[0] # Michael
classmates[1] # Bob
classmates[2] # Tracy
classmates[3] # 下标越界
classmates[-1] # Tracy,最后一个元素遍历
classmates = ['Michael', 'Bob', 'Tracy']
for classmate in classmates:
print(classmate)List列表中的元素可以是任何数据类型
L = ['Apple', 123, True]二维列表
三维、思维无限嵌套都可以,但用的很少
s = ['python', 'java', ['asp', 'php'], 'scheme']
len(s) # 输出:4
s[2][0] # 输出:'asp',二位列表的元素表示list列表中的方法
list集合为可变的有序表
list列表追加
classmates = ['Michael', 'Bob', 'Tracy']
classmates.append('Adam') # ['Michael', 'Bob', 'Tracy', 'Adam']list列表插入
classmates = ['Michael', 'Bob', 'Tracy']
classmates.insert(1, 'Jack') # ['Michael', 'Jack', 'Bob', 'Tracy', 'Adam']list列表删除
classmates = ['Michael', 'Bob', 'Tracy']
classmates.pop() # ['Michael', 'Bob']
classmates.pop(1) # ['Michael'] 删除指定索引的元素list列表替换
classmates = ['Michael', 'Jack', 'Bob']
classmates[1] = 'Sarah' #['Michael', 'Sarah', 'Bob'] 替换索引为1的元素tuple 元组
python中除了list的另一种有序列表,一旦初始化就不能修改
classmates = ('Michael', 'Bob', 'Tracy')
# 因为tuple不能改变,所以没有append(),insert()等方法不可改变,指的是classmates创建后在内存中指向的对象是不能改变的,如果是t = ('a', 'b', ['A', 'B']),那么t元组中包含这一个list列表,这个list列表是可以改变的
一个元素的tuple
t = (1,) # 输出:(1,)不能使用 t = (1) 表示,t = (1) 代表把1赋值给了t,python为了区分用“,”分隔表示元组
总结
list和tuple是Python内置的有序列表,一个可变,一个不可变
判断
条件判断格式(if)
if <条件判断1>:
<执行1>
elif <条件判断2>:
<执行2>
elif <条件判断3>:
<执行3>
else:
<执行4>条件判断从上向下匹配,当满足条件时执行对应的块内语句,后续的elif和else都不再执行
if判断条件还可以简写,比如写:
if x:
print('True')只要x是非零数值、非空字符串、非空list等,就判断为True,否则为False
模式判断(match)
如果要针对某个变量匹配若干种情况,可以使用match语句
例如:
# -*- coding: utf-8 -*-
score = 'B'
match score:
case 'A':
print('score is A.')
case 'B':
print('score is B.')
case 'C':
print('score is C.')
case _: # _表示匹配到其他任何情况
print('score is ???.')使用match语句时,我们依次用case xxx匹配,并且可以在最后(且仅能在最后)加一个case _表示“任意值”
复杂判断(match)
match语句除了可以匹配简单的单个值外,还可以匹配多个值、匹配一定范围,并且把匹配后的值绑定到变量
age = 15
match age:
case x if x < 10:
print(f'< 10 years old: {x}')
case 10:
print('10 years old.')
case 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18:
print('11~18 years old.')
case 19:
print('19 years old.')
case _:
print('not sure.')match语句的case匹配非常灵活
匹配列表
# -*- coding: utf-8 -*-
args = ['gcc', 'hello.c', 'world.c']
# args = ['clean']
# args = ['gcc']
match args:
# 如果仅出现gcc,报错:
case ['gcc']:
print('gcc: missing source file(s).')
# 出现gcc,且至少指定了一个文件:
case ['gcc', file1, *files]:
print('gcc compile: ' + file1 + ', ' + ', '.join(files))
# 仅出现clean:
case ['clean']:
print('clean')
case _:
print('invalid command.')循环
for循环
names = ['Michael', 'Bob', 'Tracy']
for name in names:
print(name)循环计算1-100之和,需要用到range()函数,range(5)可以生成一个整数序列
list(range(5)) # 输出:[0, 1, 2, 3, 4]
sum = 0
for x in range(101):
sum = sum + x
print(sum)range(5) 函数生成一个从0开始(包括0)到5(不包括5)的整数序列。但是,range 对象本身并不直接输出这些值,它更像是一个迭代器,需要通过循环来访问这些值,range(5)与range(0,5)是等效的
while循环
sum = 0
n = 99
while n > 0:
sum = sum + n
n = n - 2
print(sum)break
在循环中,break语句可以提前退出循环
n = 1
while n <= 100:
if n > 10: # 当n = 11时,条件满足,执行break语句
break # break语句会结束当前循环
print(n)
n = n + 1
print('END')continue
n = 0
while n < 10:
n = n + 1
if n % 2 == 0: # 如果n是偶数,执行continue语句
continue # continue语句会直接继续下一轮循环,后续的print()语句不会执行
print(n)break、continue 通常都必须配合if语句使用,要特别注意,不要滥用break和continue语句。break和continue会造成代码执行逻辑分叉过多,容易出错。大多数循环并不需要用到break和continue语句,上面的两个例子,都可以通过改写循环条件或者修改循环逻辑,去掉break和continue语句
python中[]表示列表,{}表示集合
当{}中包含键值对表示字典
创建空集合用set(),不能使用{},因为{}表示空字典
list、tuple、dict、set总结:
GitHub Copilot: 在Python中,`list`、`tuple`、`dict`和`set`是四种常见的数据类型,它们各自有不同的特点和用途。
- list(列表)是一种有序的可变序列,可以存储任意类型的元素。列表使用方括号`[]`来表示,元素之间用逗号`,`分隔。列表支持索引、切片、添加、删除、修改等操作,是Python中最常用的数据类型之一。
- tuple(元组)是一种有序的不可变序列,可以存储任意类型的元素。元组使用圆括号`()`来表示,元素之间用逗号`,`分隔。元组支持索引、切片等操作,但不支持添加、删除、修改等操作。元组通常用于存储不可变的数据,如坐标、颜色等。
- dict(字典)是一种无序的键值对集合,可以存储任意类型的键和值。字典使用花括号`{}`来表示,每个键值对之间用冒号`:`分隔,键值对之间用逗号`,`分隔。字典支持通过键来访问值,也支持添加、删除、修改等操作。字典通常用于存储具有映射关系的数据,如姓名和电话号码的对应关系。
- set(集合)是一种无序的元素集合,可以存储任意类型的元素。集合使用花括号`{}`来表示,元素之间用逗号`,`分隔。集合支持添加、删除、交集、并集、差集等操作。集合通常用于去重、交集、并集等操作。
需要注意的是,`list`、`tuple`、`dict`和`set`是不同的数据类型,它们之间不能直接进行转换。如果需要将它们之间进行转换,需要使用相应的转换函数,如`list()`、`tuple()`、`dict()`和`set()`。
dict
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度,dict中的key必须是不可变对象
dict优缺点
查找和插入比list快,不会随着key多增加而变慢
占用大量内存,内存浪费多
list优缺点
查找和插入事件随着元素增加而增加
占用空间小,浪费内存少
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
d['Michael'] # 输出:95存入key、value
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
d['Adam'] = 67
d # 输出:{'Michael': 95, 'Bob': 75, 'Tracy': 85, 'Adam':67}如果再次执行d['Adam'] = 80,那么会覆盖之前的value
可以使用'Bob' in d,检查key是否在字典中,如果返回ture代表存在,返回false代表不存在
查找value
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
d.get('Bob')
d.get('Bob', -1)如果在字典中不存在,例如d.get('Tom'),什么都不回输出
dict内部存放的顺序和key放入的顺序是没有关系的
删除
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
d.pop('Bob') # key与value都会删除Set
set与dict类似,也是一组key的集合,但不存储value,在set中没有重复的key
set创建需要放入一个可迭代的对象,例如列表或元组
创建
s = set([1, 2, 3])
s # 输出:{1, 2, 3}创建set要使用到list列表
set中不能放可变的对象,直接创建是已经给定了
因为set不可重复,set中的重复元素会被自动过滤,例如:s = set([1, 2, 2, 3]),输出s:{1, 2, 3}
添加
s = set([1, 2, 3])
s.add(4)
s # 输出:{1, 2, 3, 4}删除
s = set([1, 2, 3, 4])
s.remove(4)
s # 输出:{1, 2, 3}两个set的交集与并集
s1 = set([1, 2, 3])
s2 = set([2, 3, 4])
s1 & s2 # 输出:{2, 3}
s1 | s2 # 输出:{1, 2, 3, 4}python中的内置函数
绝对值
abs(-20) # 输出:20最大值
max(1, 2) # 输出:2
max(2, 3, 1, -5) # 输出:3类型转换
int('123') # 输出:123
int(12.34) # 输出:12
float('12.34') # 输出:12.34
str(1.23) # 输出'1.23'
str(100) # 输出'100'
bool(1) # 输出:True
bool('') # 输出:False函数名
就是指向一个函数对象的引用,可以把函数名赋给一个变量,相当于给函数起了一个别名
a = abs # 变量a指向abs函数
a(-1) # 输出:1将整数转换成十六进制字符串
n1 = 255
n2 = 1000
print(hex(n1), hex(n2))定义函数
定义函数使用def语句,依次写出函数名、括号、括号中的参数和冒号:,在缩进中编写函数体,函数返回值用return
def my_abs(x):
if x >= 0:
retun x
else:
retun -x空函数
定义一个什么都不做的空函数,可以使用pass
def nop():
passpass还可以用在其他语句中:
if x >= 18:
pass返回多个值
函数可以同时返回多个值,但其实就是一个tuple
import math
def move(x, y, step, angle=0):
nx = x + step * math.cos(angle)
ny = y - step * math.sin(angle)
return nx, nyimport math语句表示导入math包,并允许后续代码引用math包里的sin、cos等函数。
然后,我们就可以同时获得返回值:
>>> x, y = move(100, 100, 60, math.pi / 6)
>>> print(x, y)
151.96152422706632 70.0但其实这只是一种假象,Python函数返回的仍然是单一值:
>>> r = move(100, 100, 60, math.pi / 6)
>>> print(r)
(151.96152422706632, 70.0)原来返回值是一个tuple!但是,在语法上,返回一个tuple可以省略括号,而多个变量可以同时接收一个tuple,按位置赋给对应的值,所以,Python的函数返回多值其实就是返回一个tuple
练习
请定义一个函数quadratic(a, b, c),接收3个参数,返回一元二次方程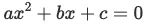 的两个解。
的两个解。
提示:
一元二次方程的求根公式为:
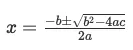
计算平方根可以调用math.sqrt()函数:
# -*- coding: utf-8 -*-
import math
def quadratic(a, b, c):
pfg = b**2 - 4*a*c
x1 = (-b + math.sqrt(pfg))/(2*a)
x2 = (-b - math.sqrt(pfg))/(2*a)
return x1, x2
# 测试:
print('quadratic(2, 3, 1) =', quadratic(2, 3, 1))
print('quadratic(1, 3, -4) =', quadratic(1, 3, -4))
if quadratic(2, 3, 1) != (-0.5, -1.0):
print('测试失败')
elif quadratic(1, 3, -4) != (1.0, -4.0):
print('测试失败')
else:
print('测试成功')函数的参数
位置函数
def power(x, n):
s = 1
while n > 0:
n = n - 1
s = s * x
retrun spower(x, n)函数有两个参数:x和n,这两个参数都是位置参数,调用函数时,传入的两个值按照位置顺序依次赋给参数x和n
默认参数
def enroll(name, gender, age=6, city='Beijing'):
print('name:', name)
print('gender:', gender)
print('age:', age)
print('city:', city)
enroll('张三', '男') # 输出:name:张三 gender:男 age:6 city:Beijing
enroll('李四', '男', city='TianJin') # 输出:name:李四 gender:男 age:6 city:TianJin这里的age与city就是默认参数,在调用传参的时候如果不指定age,city就会输出默认参数,如果传入age,city就会改变默认参数,输出的当前传入参数
定义默认参数要牢记一点:默认参数必须指向不变对象!(不使用不变对象的话有坑)
可变参数
可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,还可以是0个,参数前加*号
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
calc(1,2) # 可以传多个参数
calc() # 可以传0个参数
list = [1,2,3,4,5]
calc(*list) # 可以传list、tuple,需要在列表、元组前加*参数前面加了一个*号,此时的numbers就是可变参数
关键字参数
可以传入0个或任意个含参数名的参数,这些新传入的关键字参数会自动组装为一个dict
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
# 普通类型传入
person('Bob', 18, city='Hainan')
person('Bob', 18, city='Hainan', job='pythoner')
# 字典传入
extra = {'city': 'SanYa', 'job': 'coder', 'email':'@a.com'}
person('Bob', 18, **extra)**extra表示把extra这个dict的所有key-value用关键字参数传入到函数的**kw参数,kw将获得一个dict,注意kw获得的dict是extra的一份拷贝,对kw的改动不会影响到函数外的extra。
命名关键字参数
限制关键字参数的名字,可以使用命名关键字参数,例如只接收city,job作为关键字参数:
和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数
def person(name, age, *, city, job):
print(name, age, city, job)
person('Jack', 24, city='Beijing', job='Engineer')